인덱스
방대한 데이터에서 검색 시 앱의 쿼리 속도를 향상시키기 위한 방법
인덱스는 선택한 속성을 기반으로 정렬된 목록으로 볼 수 있습니다.
예를 들어 caryou라는 블로그를 검색해야할 일이 있다고 하면 c로 시작하지 않는 블로그는 전부 무시하고 검색이 가능합니다. 정렬이 안되어있다면..? 'c'로 시작하는 모든 블로그를 큰 무작위 목록에서 가져와야 합니다.
인덱스의 작동 방식
인덱스를 추가할 때 목록 위젯의 정렬 속성처럼 작동하는 하나 이상의 속성을 선택해야 합니다. 이 인덱스는 선택한 속성과 레코드 ID만 있는 추가 테이블을 생성합니다.
'T'로 시작하는 이름을 검색하기 시작한다고 가정해 보겠습니다. 데이터베이스는 먼저 인덱스 테이블을 살펴보고, 제한된 레코드 목록을 정의하고, ID를 가져오고, ID로 데이터베이스 테이블에서 전체 레코드를 검색합니다.
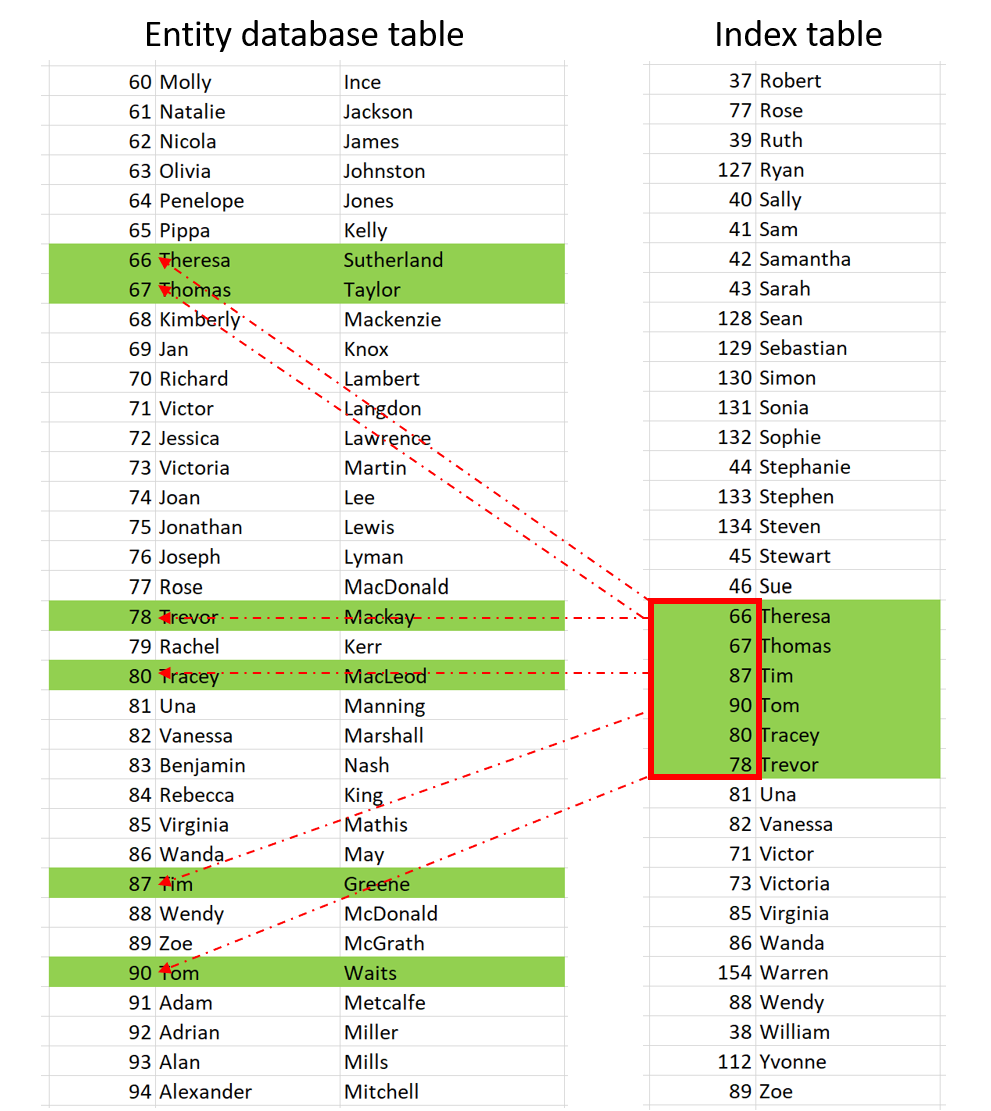
본 글에서는 내용을 다루진 않았지만
약 100,000개의 데이터에서 검색을 수행했을 시 인덱스를 썼을 때와 안썼을 때를 비교해보면 약 4배에서 8배 더 빠름을 확인을 할 수 있었습니다.
다만 현명하게 사용해야 합니다.
인덱스를 사용하면 쿼리 속도가 크게 빨라지지만 새 레코드가 추가되거나 기존 레코드가 변경될 때마다 관련 인덱스 테이블도 업데이트해야 합니다.
최종 사용자가 읽기작업이아닌 쓰기 작업을 가장 많이 수행한다면 (작은) 성능 영향을 미치므로 잠재적으로 사용자 경험이 저하될 수 있습니다.
인덱스의 결과는 인덱스 페이지 업데이트로 인해 더 빠른 검색(읽기 작업)과 더 느린 개체 생성(쓰기 작업)입니다.
인덱스가 의미 있을 때
1. 큰 테이블에서
2. 가장 자주 검색되는 속성에 대해. ex) Staff - FullName
3. 고유 값이 많은 속성에 대해 ( 문자열 ) / Bool값은 true와 false밖에 없기에 좋은 인덱스가 아닙니다.
4. 데이터를 쓰는 것보다 읽는 경우가 더 많은 경우.
- main index 속성은 목록 위젯의 정렬 속성과 같습니다.
- 인덱스에 사용되는 속성에 첨부된 검색 필드의 비교는 Equals 또는 Starts with여야 하며 Ends with 또는 Contains가 되어서는 안 되며, 그렇지 않으면 인덱스는 쓸모가 없습니다.
- 'string – unlimited' 속성에 인덱스를 추가하지 마십시오, 이렇게 하면 인덱스 페이지가 커집니다.
'LowCode (Mendix) Advanced > Advanced Domain Model Skills' 카테고리의 다른 글
| Date Time Handling (0) | 2024.09.06 |
|---|---|
| Advanced Associations Using Self Reference (0) | 2024.09.06 |
| Improving App Performance with Indexes and Reference Sets (0) | 2024.09.04 |
| Using the FileDocument and Image Entity (0) | 2024.06.21 |
| Inheritance - being special and one of a kind (0) | 2024.06.18 |